
|
|
『COMPASSシミュレーションモデルに対するデータマイニング』
【シミュレーション】【統合型データベース、モデル解析】【データマイニング】【相関ルール】【知識獲得】
■ 研究者
■ 研究内容の概要: 本研究では、シミュレーションモデルによって蓄積された出力データに対してデータマイニング技術を応用することで、見失いかねない価値ある情報を発掘することを可能とした。 シミュレーションモデルは実システムで実行不可能な政策実験の場として有効な手段になりうるが、詳細な描写はモデルの複雑化と巨大化を招く。さらに出力結果から意味のある情報を獲得するという作業は、従来の仮説検定的な分析視点と分析者のデータ処理能力のみでは困難を伴う。 本研究で示した手法により、データの有効活用を目的とした分析が可能となった。具体的には、データをもって仮説を抽出することに成功した。従来の仮説検定的な分析は、分析者が設定した仮説をデータでもって裏付ける作業であったが、今回開発した手法は、データ自身にルールを語らせていると捉えることができ、分析者のデータ処理能力を超えた領域をカバーしうると考えられる。 ■ 研究内容の詳細: 本研究では、膨大な量のデータの有効活用を目的として、シミュレーションモデルによって蓄積された出力データに対してデータマイニング技術を応用し、有用な情報の抽出を行った。 シミュレーションが有効なのは [1] システムが複雑で予測が困難な場合、[2] 実システムで試すには時間やコストがかかり過ぎる場合、[3] 実システムでは危険が伴う場合、[4] 実システムがまだ存在しない場合、[5] 複数の解をそれぞれ比較したい場合、などが挙げられる。また、その対象システムが極めて限定的であったり、仮定や仮説が多用され、システムが現実とかけ離れてしまっている例が少なくない。しかし事象の詳細な描写はモデルの複雑化と巨大化を招く。詳細なシミュレーションのために、膨大なデータを用いるものの、同時に出力される膨大な量のデータを活用しきれてない場合もある。出力結果から意味のある情報を獲得するという作業は、従来の仮説検定的な分析視点と分析者のデータ処理能力のみでは困難を伴う。このようにシミュレーションモデルは事象の説明能力と結果の理解のしやすさの間にトレードオフの関係を持っている。 データマイニングとは、データを知識としてより戦略的に活用する技術の総称である。一般的には企業における顧客管理の拡充、ニーズ分析を目的として利用されており、1990年代から発展してきている分野である。データマイニングの発展の背景には、顧客重視の企業経営とマーケティング、顧客データの大規模化とデータベースの整備、データ解析技術と計算機処理能力の向上、などがあげられる。 本研究では、上述したシミュレーションが抱えるジレンマを踏まえ、データマイニング技術を経済・貿易・金融・エネルギーの統合型データベースに応用した。連続値である統計データやシミュレーションモデルの出力値をカテゴリー化することで意味を付与し、新しい分析手法の領域を開拓した。この手法により、出力データに対する効率的な分析と、通常はデータの中に埋もれかねない情報の発掘を可能とした。また、データ自体から仮説を抽出する技術と、人間の分析能力を超えた計算能力を用いることで、シミュレーションモデルによって蓄積されたデータを有効に活用する可能性を示した。 2002年度は、分析システムのプロトタイプ作成と、分析システムの実証研究を行った。結果として、COMPASSシミュレーションモデルに対するデータマイニングの実行可能性を確認し、分析者が利用可能な分析システムの構築に成功した。 その他にも、ネットワークを介した分析環境の実現を行った。TCP/IPが利用できる環境であれば、技術的にはどこからでも分析の実行が可能であるが、セキュリティ上の配慮から、鵜野研究室のローカルエリアネットワーク内でのみ利用を許可している。その他の場所からの接続も、申請ののち利用許可を解放することが可能である。 最後に「COMPASSシミュレーションモデルに対するデータマイニング〜分析システム構築に関するレファランスマニュアル」(寺岡、2003)を作成し、知識の共有化と財産化を計った。 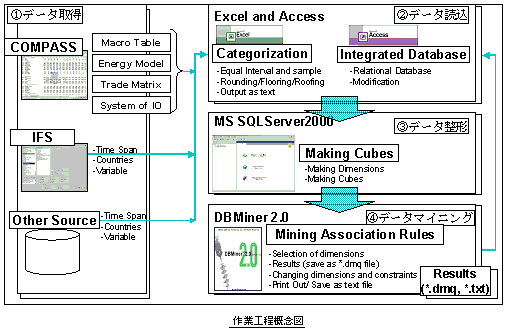
分析システムの構築に関する作業は、大きく4つの段階に分けることが出来る:
データの[1]取得、[2]整形、[3]読み込み、そして[4]データマイニングである。
■ プロジェクト2(次世代サイバーノレッジの研究)における本研究の位置付け: 本研究は次世代サイバーノレッジ・グループにおいて、データベースやシミュレーションによる理論研究と実社会における実証研究の接点となる研究としての位置を占める。 ■ 研究の発展方向 引き続き2003年度は、構築した分析システムの拡充を行う。具体的には、データの対象期間の拡大、分析に用いることが可能な変数の追加、そして抽出されたルールの検証方法の研究を行う。いずれの作業もシステム構築者と政策分析者の協働作業が必要とされる。 また長期的な計画としてモデル設計者との連携を強め、出力結果と分析システムを直結できるモデル設計を予定している。現在、COMPASSモデルではOLAPツールの導入に向け、OLAP部門とシミュレーションモデル部門の担当者が協働でデータフォーマットの設計にあたっている。 今後の展望として、本研究で示した手法を用いて、予測値に対する「逆引き辞典」の構築が検討できる。これは観測値から抽出されたルールが、予測値に当てはまるか否かによって検定を行う分析である。シナリオ分析や、ある変数の影響分析を行う手法も研究する価値があると考えられる。これらの手法を組み合わせることで、シミュレーションモデルが不確実性を含む政策決定に貢献できると考える。 ■ 関連URL http://web.sfc.keio.ac.jp/~unodb/ |

